Und was sind hochdimensionale Daten? Und was sind Anwendungsfälle für Vektordatenbanken? Und…
In diesem Artikel werden Vektordatenbanken inklusive Anwendungsfälle beschrieben sowie ein Beispiel mit der PostgreSQL Extension pg_vector. Der Source Code steht zur freien Verfügung.
Vektordatenbanken und Vektoren
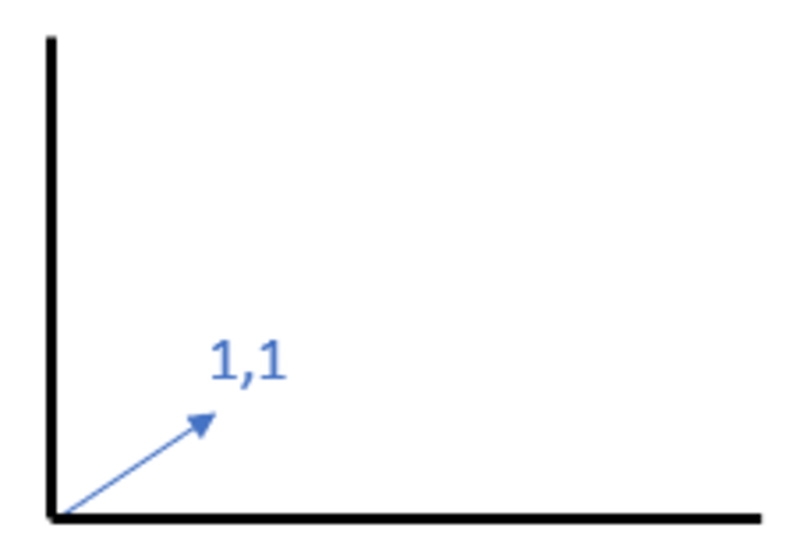
Eine Vektordatenbank dient der effizienten Speicherung und Verarbeitung von Vektordaten. Vektoren werden durch einen Pfeil im Raum repräsentiert wie der in Abbildung 1 dargestellte zweidimensionale Vektor [1,1].
→ siehe Abbildung 1 rechts: Zweidimensionaler Vektor (zum Vergrößern klicken)
Beim maschinellen Lernen werden mehrdimensionale Vektoren als "Embeddings" bezeichnet und als Arrays mit Zahlen repräsentiert. Beispielsweise könnte der Text "PostgreSQL ist eine Datenbank" als Vektor [-0.003, -0.088, …, -0.005] gespeichert werden (siehe Abbildung 2).
→ siehe Abbildung 2 rechts: Embedding (zum Vergrößern klicken)
Es existieren eigenständige Vektordatenbanken wie Pinecone. Außerdem werden existierende relationale und NoSQL-Datenbanken um Vektor-Funktionalitäten erweitert. Im Falle einer relationalen Datenbank wird für die Erstellung einer Tabelle ein entsprechender Vektor-Datentyp benötigt, um Vektoren speichern zu können. Außerdem werden Funktionen für die Auswertung der Vektoren (z.B. Ähnlichkeitsmetrik, um die nächsten Nachbarn zu finden) benötigt.
Anwendungsfälle
Typische Anwendungsfälle für Vektordatenbanken sind unter anderem:
- Empfehlungssysteme
Vektor-Datenbanken können Nutzerpräferenzen und Produktdaten in Vektorform speichern, um personalisierte Empfehlungen zu generieren. Beispielsweise kann ein Empfehlungssystem für Filme die Sehgewohnheiten und Vorlieben eines Nutzers mit einem Katalog von Filmen abgleichen, um die relevantesten Vorschläge zu machen. - Bild- und Videosuche
In der Bild- und Videosuche ermöglichen Vektor-Datenbanken die Speicherung von Multimedia-Objekten als Vektoren, die durch maschinelles Lernen aus den visuellen Inhalten abgeleitet werden. Anwender können nach Bildern oder Videos suchen, die visuell ähnlich sind. - Natürlichsprachliche Verarbeitung (NLP)
Vektor-Datenbanken spielen eine Schlüsselrolle in der NLP, indem sie die Verarbeitung und Analyse von Textdaten in Form von Wort- oder Satzvektoren unterstützen. Anwendungen umfassen die semantische Textsuche, Chatbots, Sentiment-Analyse und automatische Zusammenfassungen. - Anomalie-Erkennung
In der Überwachung von beispielsweise IT-Netzwerken, der vorbeugenden Wartung und der Qualitätssicherung können Vektor-Datenbanken genutzt werden, um Anomalien in Echtzeit zu erkennen. Durch die Analyse von Betriebsdaten als Vektoren können ungewöhnliche Muster identifiziert werden, die auf Probleme oder Ausfälle hinweisen.
Beispiel mit VektorDB-Erweiterung pg_vector
Nachfolgend ist ein Beispiel aufgeführt, wie eine um Vektorfunktionalitäten erweiterte relationale Datenbank genutzt werden kann.
Schritt 1: Einrichtung der PostgreSQL-Datenbank mit VektorDB-Erweiterung
Zunächst muss PostgreSQL mit der VektorDB-Erweiterung pg_vector installiert werden. Für einen schnellen Start eignet sich ein Docker-Container zum Testen (docker pull pgvector/pgvector:pg16).
-- pg_vector Erweiterung aktivieren
CREATE EXTENSION IF NOT EXISTS pg_vector;
Schritt 2: Datenmodellierung
Für ein Empfehlungssystem könnten zwei Tabellen definiert werden: eine für Besucher einer Konferenz und eine für Vortragstitel auf der Konferenz. Die Tabellen enthalten Vektorrepräsentationen (Präferenzen bzw. Eigenschaften).
CREATE SCHEMA vector;
-- Tabelle für Besucher mit ihren Präferenz-Vektoren
CREATE TABLE vector.visitor (
user_id SERIAL PRIMARY KEY,
preferences VECTOR(768)
);
-- Tabelle für Vortragstitel mit ihren Eigenschafts-Vektoren
CREATE TABLE vector.topic (
item_id SERIAL PRIMARY KEY,
properties VECTOR(768)
);
Schritt 3: Einfügen von Daten
Im nächsten Schritt werden die Vektorrepräsentationen der Besucher- und Vortragstiteldaten eingefügt. Diese Vektoren können beispielsweise mit Hilfe von frei verfügbaren Python-Paketen, die auf BERT, OpenAI, o.ä basieren, erzeugt werden.
Im Beispiel werden vier Vortragstitel aus der im Mai 2024 stattfindenden DOAG-Datenbank-Konferenz (DOAG 2024 Datenbank mit Exaday) sowie die Präferenzen von zwei möglichen Besuchern in embeddings überführt. Die Funktion generate_embeddings wandelt mit Hilfe von Bert die Texte in Vektoren um. Anschließend werden die Vektoren in die erstellten PostgreSQL-Tabellen eingefügt. Der vollständige Quellcode kann dem oben erwähnten github-Verzeichnis entnommen werden.
# Testdaten
user_preferences = ["Oracle Vector DB",
"PostgreSQL"]
item_properties = ["Wrap up your PostgreSQL environment with TPA",
"Enabling Generative-AI with Oracle AI Vector Search",
"Oracle DBMS meets Generative AI: from Text-to-SQL to Vector DB",
"Is PostgreSQL catching up with the Oracle Database?"
]
# Generieren von Embeddings für Besucherpräferenzen und Titeleigenschaften
user_embeddings = [generate_embedding(text) for text in user_preferences]
item_embeddings = [generate_embedding(text) for text in item_properties]
# Einfügen von Embeddings in die Datenbank
user_insert_query = "INSERT INTO vector.visitor (preferences) VALUES (%s)"
item_insert_query = "INSERT INTO vector.topic (properties) VALUES (%s)"
execute_batch(cursor, user_insert_query, [(embedding,) for embedding in user_embeddings])
execute_batch(cursor, item_insert_query, [(embedding,) for embedding in item_embeddings])
Schritt 4: Abfrage von Empfehlungen
Um Empfehlungen abzufragen, kann eine Ähnlichkeitssuche zwischen den Präferenzvektoren der Besucher und den Eigenschaftsvektoren der Vortragstitel durchgeführt werden. Das Ziel ist es, Vorträge zu finden, die den Besuchern empfohlen werden können, das heißt Eigenschaftsvektoren der Vortragstitel und Präferenzvektoren der Besucher liegen nahe beisammen. Für die Suche stehen Operationen wie Euklidische Ähnlichkeit (<->) oder Kosinus-Ähnlichkeit (<=>) zur Verfügung.
-- Abfrage von Empfehlungen für einen spezifischen Benutzer mit Hilfe Euklidischer Ähnlichkeit
SELECT item_id,
properties <-> (SELECT preferences FROM vector.visitor WHERE user_id = 1) AS similarity
FROM vector.topic
ORDER BY similarity
LIMIT 10;
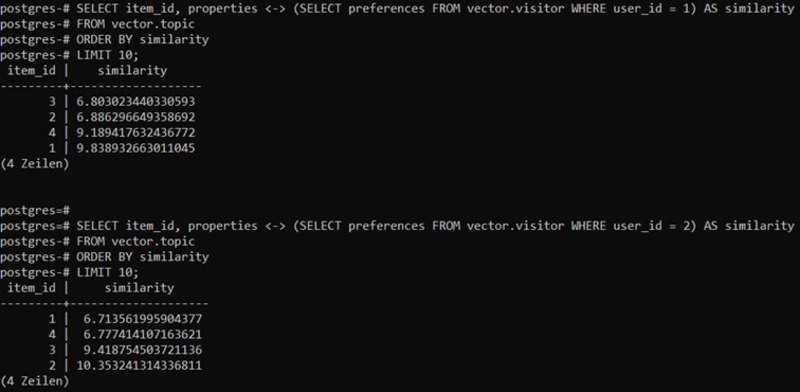
Diese Abfrage vergleicht den Präferenzvektor eines bestimmten Benutzers (user_id = 1) mit den Eigenschaftsvektoren aller Vortragstitel und sortiert die Ergebnisse nach ihrer Ähnlichkeit. Die Top-N-Ergebnisse könnten dann als personalisierte Empfehlungen dem Besucher präsentiert werden. Das Ergebnis von zwei Abfragen ist in Abbildung 3 zu sehen:
- dem ersten Besucher (user_id 1) mit Präferenz "Oracle Vector DB" werden die Vorträge "Oracle DBMS meets Generative AI: from Text-to-SQL to Vector DB" (item_id: 3) und “Enabling Generative-AI with Oracle AI Vector Search” (item_id: 2) empfohlen. Die PostgreSQL-Vorträge sind erwartungsgemäß schlechter eingestuft.
- dem zweiten Besucher (user_id 2) mit Präferenz "PostgreSQL" werden die Vorträge "Wrap up your PostgreSQL environment with TPA" (item_id: 1) und "Is PostgreSQL catching up with the Oracle Database?" (item_id: 4) empfohlen werden. Die Oracle-Vector-DB-Vorträge sind erwartungsgemäß schlechter eingestuft.
→ siehe Abbildung 3 rechts: Ergebnis Ähnlichkeitssuche (zum Vergrößern klicken)
Für ein produktionsreifes Empfehlungssystem müssen weitere Überlegungen wie Optimierung der Treffer in der Ähnlichkeitssuche oder Skalierbarkeit angestellt werden. Die PostgreSQL extension pg_vector bietet beispielsweise Vektorindexe wie HNSW (Hierarchical Navigable Small World) für die hoch performante Annäherung der nächsten Nachbarn in hochdimensionalen Räumen.
Fazit
Das Beispiel ist sehr vereinfacht und zeigt die prinzipielle Funktionsweise von Vektordatenbanken auf. Durch die Nutzung von Vektoroperationen können komplexe Ähnlichkeitssuchen effizient durchgeführt werden. Für die verwendeten Datensätze hätte man auch einen Textindex verwenden können. Vektoren und Ähnlichkeitssuchen spielen jedoch ihre Stärke bei semantischen Zusammenhängen aus, wenn zum Beispiel nach einem Pudel gesucht wird und auch Treffer für Hund gezeigt werden, da beide Vektoren nahe beieinander liegen.
Die Berechnung der Embeddings erfolgte mit einem frei verfügbaren Large-Language-Modell (LLM). Für eine interne Applikation wird man kein öffentliches Modell verwenden, das die Daten möglicherweise zum Training wiederverwendet. Zukünftig ist zu erwarten, dass die Berechnung der Embeddings mit Hilfe von eingebauten Datenbank-Funktionen gestartet werden kann anstatt mittels Python wie im Beispiel. Auch hier muss sichergestellt sein, dass die sensitiven, unternehmensinternen Daten nicht durch den Cloud-Anbieter zum Training und Verbesserung des LLMs wiederverwendet werden. Idealerweise ist der Zugriff auf das LLM konfigurierbar und kann durch ein eigenes ersetzt werden.
Relationale Datenbanken wie PostgreSQL oder Oracle werden zunehmend um Vektorfunktionen erweitert, so dass neben der neuen Funktionalität auch der bekannte und bewährte “relationale” Funktionsumfang zur Verfügung steht.
Andreas Buckenhofer