Ob Sie schon bald auf die aktuelle Datenbankversion umsteigen möchten oder dieser Schritt erst später ansteht – ein Blick auf die Security-Themen rund um Oracle Database 12c lohnt sich auf jeden Fall. Zur ersten Orientierung zeigen wir einige Neuigkeiten aus dem Standardlieferumfang der Datenbank, aus den Optionen Advanced Security und Database Vault sowie aus dem Data Masking Pack des Oracle Enterprise Manager Cloud Control.
Unified Auditing: Flexibler, schneller, sicherer
Im Laufe der Jahre hat sich im Bereich des Auditings eine etwas unübersichtliche Reihe von Möglichkeiten und Speicherformen entwickelt. Diese kann man nach wie vor nutzen, allerdings voraussichtlich zum letzten Mal. Denn zusätzlich gibt es ein komplett überarbeitetes, völlig neues Auditing: das sogenannte unified auditing.
Der DBA kann zwischen den beiden Varianten wählen. Es wird jedoch empfohlen, die neue Variante zu nutzen, die bei Neuinstallationen auch grundsätzlich konfiguriert ist. Bei älteren Datenbanken, die auf die neue Software umgestellt werden, muss das neue Auditing durch Hinzulinken eines speziellen Codeteils aktiviert werden.
Was zeichnet das neue Auditing aus?
Alle Audit-Daten werden beim unified auditing innerhalb der Datenbank in einer einzigen, partitionierten Tabelle gespeichert. Die Tabelle und die übrigen Objekte, die den Audit-Trail ausmachen, sind im Tablespace SYSAUX abgelegt. Sie können allerdings sehr leicht in ein anderes Tablespace verlagert werden.
Der Audit-Trail gehört dem Benutzer AUDSYS, der nicht mit DROP USER gelöscht werden kann. Zusätzlich sind zwei Rollen implementiert: AUDADMIN und AUDVIEWER. Sie berechtigen zur Administration bzw. zum Lesen des Audit-Trails. Der Eigentümer eines Objekts kann das neue Auditing nur dann verwenden, wenn er auch über die Rolle AUDADMIN verfügt.
Das unified auditing ist unabhängig von Initialisierungsparametern. Wie beim bekannten „Fine Grained Auditing“ (FGA) wird es über Regeln (policies) und dem Aktivieren dieser Regeln mit dem Befehl AUDIT gesteuert.
Audit-Policies sind neue Datenbankobjekte. Sie enthalten eine beliebige Reihe von AUDIT-Einstellungen, die dann als Ganzes weitergegeben und aktiviert werden können. Da Policies zum Beispiel Bedingungen für das Schreiben von Audit Einträgen enthalten können, ist es endlich auch möglich, Ausnahmen zu formulieren, für die kein Audit-Eintrag geschrieben werden soll.
Das ist zum Beispiel extrem hilfreich, wenn eine Anwendung selbst einen eigenen Audit-Trail schreibt. Als DBA könnte man dann auf der Datenbankseite nur noch die Aktionen auditieren, die die Anwendung umgehen.
Performance
Das neue Auditing ist zusätzlich leistungsfähiger geworden. Es wird über eine Queue in der SGA abgewickelt. Diese kann man im Hinblick darauf steuern, wann die Audit Einträge in die Datenbank geschrieben werden: Wie bisher unmittelbar nach dem zu auditierenden Ereignis oder verzögert gemeinsam mit anderen dirty blocks der SGA.
Wenn man dann noch bedenkt, dass mit dem unified auditing auch Aktionen des SQL*Loader, der Data Pump und von RMAN auditierbar werden, sollte sich das unified auditing schnell als Standardvariante des Auditings durchsetzen.
Data Redaction & Data Masking: Datenanonymisierung für Anwendungen, Entwicklung und Test
Data Redaction
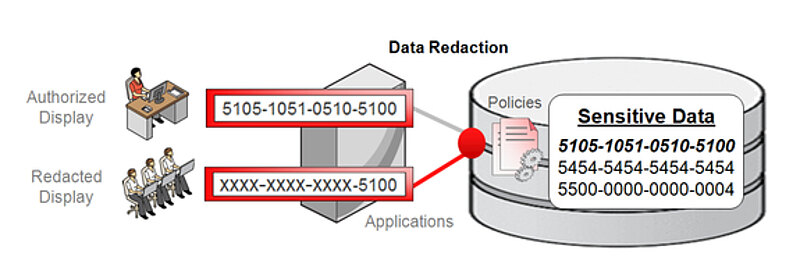
Unter data redaction versteht man bei Oracle das Verändern von Daten ausschließlich für die Ausgabe. Die ursprünglichen Daten werden demnach nicht verändert.
Eigentlich kennt jeder data redaction aus eigener Erfahrung: Auf dem Kassenbeleg einer Kreditkartenzahlung sind nicht alle Ziffern der Kreditkartennummer ausgegeben, sondern nur die letzten Ziffern. Die übrigen sind durch * oder - unkenntlich gemacht. Das Unkenntlich-Machen geschieht über die Anwendung.

Mit Oracle Data Redaction kann das Unkenntlich-Machen nun direkt in der Tabelle bei den Daten hinterlegt werden und gilt damit für jeden Zugriff, der zu einer Bildschirm- oder Druckausgabe führt. Die Kreditkartennummern können aber nach wie vor für WHERE Bedingungen, in INSERTs, UPDATEs und DELETEs, für Berechnungen und für das Anlegen von Indizes verwendet werden.
Data redaction wird über das Package DBMS_REDACT gesteuert, das nur verwendet werden darf, wenn die Advanced Security Option lizenziert ist.
Das Package stellt vier Möglichkeiten des Unkenntlich-Machens zur Verfügung:
- FULL: Der gesamte Wert wird durch eine Konstante ersetzt.
- PARTIAL: Ein Teil des Werts wird ersetzt.
- RANDOM: Der gesamte Wert wird durch einen Zufallswert ersetzt.
- REGEXP: Der Wert wird mit Hilfe eines regulären Ausdrucks durchsucht. Ist die Suche erfolgreich, wird die gefundene Zeichenkette ersetzt.
Die Veränderungen können für unterschiedliche Benutzer unterschiedlich gestaltet werden. Nur der Benutzer SYS bildet eine Ausnahme. Für ihn wird das Unkenntlich-Machen nicht durchgeführt, denn er verfügt über das Privileg EXEMPT REDACTION POLICY.
Data Masking
Im Unterschied zum unkenntlich Machen bei Ausgaben, werden beim Maskieren mit dem Data Masking Pack des Enterprise Managers Cloud Control Produktionsdaten nachhaltig verändert. Dabei behalten sie typische Eigenschaften wie Primär- / Fremdschlüsselbeziehungen oder ihre Verteilungscharakteristika: Der Name MÜLLER kommt in einer deutschen Namensliste eben häufiger vor. Beim Maskieren würde ein anderer deutscher Name mit einer vergleichbaren Häufigkeit in der Namensliste erscheinen.
Während bisher eine Staging-Datenbank benötigt wurde, in der die zuvor duplizierten Produktionsdaten maskiert wurden, kann man nun Daten maskieren und direkt in Dateien im „Data Pump Export“-Format schreiben. Diese Export-Dateien können dann in Test- oder Entwicklungssysteme importiert werden.
Privilegien: Monitoring von Privilegien und neue Privilegien
Beschäftigt man sich mit den Privilegien von Benutzern und Rollen, so ist über die vorhandenen Data-Dictionary-Views relativ leicht festzustellen, über welche Privilegien ein Benutzer oder eine Rolle verfügt. Allerdings kann häufig nicht festgestellt werden, ob diese Privilegien tatsächlich benötigt werden. Das machte das Durchsetzen des sogenannten least privilege (Prinzip der minimalen Berechtigungen) fast unmöglich.
Das Package DBMS_PRIVILEGE_CAPTURE aus der neuesten Version der Option Oracle Database Vault schafft hier Abhilfe. Es erzeugt eine Liste der in einem festzulegenden Zeitraum verwendeten Privilegien und zeigt auf welchem Weg, zum Beispiel direkt oder über Rollen, diese Privilegien zugewiesen wurden.
Das neue Datenbank-Release bietet aber auch eine Reihe neuer Privilegien, die die bisher häufige Verwendung des Privilegs SYSDBA reduzieren. So können jetzt eigene Gruppen für die Bereiche Backup, Keystore / Wallet und Standby Management festgelegt werden. Sie werden unter UNIX und Linux genauso angelegt, wie das schon bisher für die DBA Gruppe geschah.
Es werden also Betriebssystemgruppen für die einzelnen Bereiche eingerichtet, dann werden diesen Gruppen auf der Betriebssystemebene Benutzer zugewiesen. Bei der Installation der Oracle-Software werden die Namen der Gruppen angegeben. Die zu diesen Gruppen gehörenden Benutzer können sich nach der Installation bei der Datenbank zum Beispiel mit sqlplus / as sysbackup zur Durchführung eines Backups anmelden. Sie haben alle Berechtigungen, die sie für das Backup benötigen, aber sie können zum Beispiel keine Prozeduren oder Packages anlegen, ändern oder löschen.
Zusätzlich zu diesen frei zu benennenden Gruppen gibt es analog zum Privileg SYSDBA neue Privilegien namens SYSDG, SYSBACKUP und SYSKM. Wie bei Connects AS SYSDBA wird das sogenannte current schema für diese Connects auf SYS gesetzt. Das führt dazu, dass alle Objekte, die als SYSDG usw. angelegt werden, im Schema SYS liegen. Im Gegensatz dazu wird der current user bei diesen Connects je nach verwendetem Aufruf auf SYSDG, SYSKM oder SYSBACKUP gesetzt. Das wiederum ist notwendig, damit im Rahmen des Auditings feststellbar bleibt, wer für welche Aktivitäten verantwortlich ist.
Drei kostenfreie, halbtägige Veranstaltungen im Oktober informieren ausführlicher über die hier behandelten Themen. Die Events finden
Für Tipps aus allen Bereichen der Datenbankadministration sei hier auch wieder auf die deutschsprachige DBA Community hingewiesen. Sie finden sie unter folgendem Link. |